引言
在实际业务场景中,很多时候在处理复杂任务的时候,会拆分上下游各个环节,形成一个类似于流水线的处理方式。上游类似于生产者,下游要依赖上游的输出进行工作,类似于消费者。但是,很多时候,上游和下游由于工作的复杂程度、环境、性能等,处理的速率不是太匹配。为了保证上下游各自按照自己的速率运转,从而保证最高的处理性能,通常的做法是引入一个中间件,比如缓存、消息队列。从而实现速率的匹配,以及对不同繁忙程度的任务进行削峰填谷,实现处理性能的平滑效果。
本文通过一个简化的生产者消费者模型,以及Queue的使用,来展现关于上述不同环节工作的协同与解耦的需求的实现。
本文的主要内容有:
1、生产者消费者模型
2、基于deque实现生产者消费者模型
3、基于Queue实现生产者消费者模型
4、deque与Queue的简单比较
生产者消费者模型
生产者消费者模型是一种常见的并发编程设计模式,适用于多个生产者和消费者之间进行任务或数据的共享与传递,从而实现解耦与高效协作。
该模型的核心思想是将生产数据的线程(生产者)与消费数据的线程(消费者)通过一个缓冲区(一般是线程安全的队列)进行连接。
实际工作中,有不少适用于生产者消费者模型的典型场景,简单列举如下:
1、任务调度系统
任务调度器充当生产者,将触发了待执行的任务放到队列中,多个工作线程充当消费者,从队列中取出任务进行执行。
2、日志处理系统
日志生成的线程充当生产者,将日志记录放入队列中,日志处理线程从队列中获取日志,进行相应的存储、分析等。
3、数据库连接池
客户端作为生产者请求数据查询操作,数据库连接池中的线程作为消费者接收客户端的请求,进行相应的查询处理,并返回结果。
4、流媒体服务器
视频编码器将视频帧数据放入队列中,流媒体服务器从队列中取出帧数据进行传输。
可以看到,涉及到复杂任务的拆解、解耦,同时需要进行上下游协同的需求场景,都很适合使用生产者消费者模型来实现。
下面通过deque和Queue分别来尝试模拟如下生产者消费模型的简单实现:
1、有2个工人,负责产品的生产,产品生产完成后放到仓库中。
2、有3个销售人员,负责产品的销售,销售的产品从仓库中出库,经过物流给到客户手中。
3、仓库是有成本的,所已存储空间是有限的,加入仓库最多存10个产品。
基于deque实现生产者消费者模型
首先我们通过Python中的deque这个集合类型,来尝试实现上面的生产者消费者模型的模拟需求。
直接看代码:
python">from collections import deque
from threading import Lock, Thread
import time
class Worker(Thread):
def __init__(self, warehouse, lock):
super().__init__()
self.warehouse = warehouse
self.lock = lock
def run(self):
while True:
with lock:
print(f'准备生产产品,当前库存:{len(self.warehouse)}')
self.warehouse.append('这是个产品')
print('生产完成')
time.sleep(0.5)
class Sales(Thread):
def __init__(self, warehouse, lock):
super().__init__()
self.warehouse = warehouse
self.lock = lock
def run(self):
while True:
with lock:
try:
print(f'成功开单,准备出库,当前库存:{len(self.warehouse)}')
self.warehouse.popleft()
print('销售完成')
except IndexError as e:
print('暂时没有可销库存')
time.sleep(0.5)
if __name__ == '__main__':
warehouse = deque(maxlen=10)
lock = Lock()
for i in range(2):
Worker(warehouse, lock).start()
for i in range(3):
Sales(warehouse, lock).start()
对上面的代码简要说明一下:
1、由于是多线程并发,而deque是非线程安全的,所以需要用到锁。
2、deque是非阻塞的,在队列满和空的时候,会有相应的异常处理逻辑。
程序的执行结果如下:

基于Queue实现生产者消费者模型
接下来看一下,通过本文的主角Queue来实现生产者消费者模型。
直接看代码:
python">from threading import Thread
from queue import Queue
import time
class Worker(Thread):
def __init__(self, warehouse):
super().__init__()
self.warehouse = warehouse
def run(self):
while True:
print(f'准备生产产品,当前库存:{self.warehouse.qsize()}')
self.warehouse.put('这是个产品')
print('生产完成')
time.sleep(0.2)
class Sales(Thread):
def __init__(self, warehouse):
super().__init__()
self.warehouse = warehouse
def run(self):
while True:
print(f'成功开单,准备出库,当前库存:{self.warehouse.qsize()}')
self.warehouse.get()
print('销售完成')
time.sleep(0.2)
if __name__ == '__main__':
warehouse = Queue(maxsize=10)
for i in range(2):
Worker(warehouse).start()
for i in range(3):
Sales(warehouse).start()
从代码量来看,稍微简洁一些,我们不需要额外引入锁了,也不需要进行异常判断。也能实现同样的执行效果。
结合源码,来简单看一下Queue的实现:
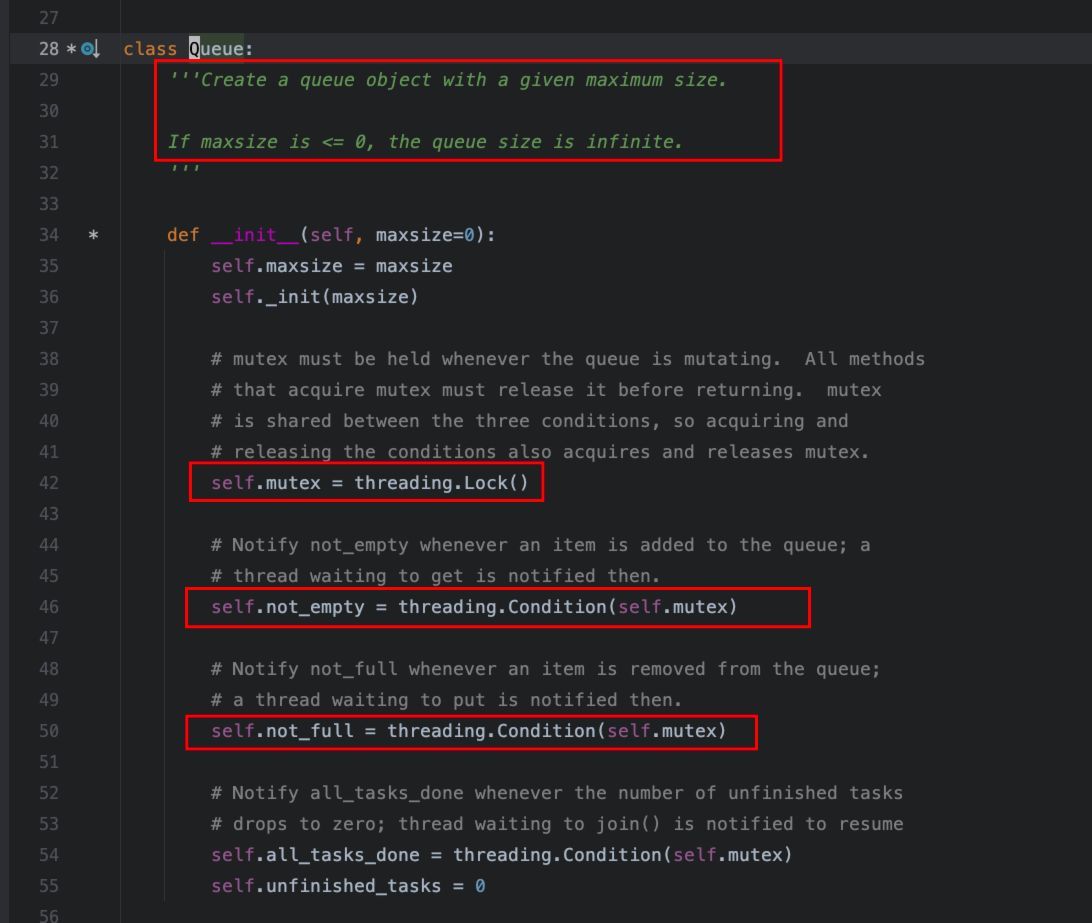
从源码中,可以知道,Queue = deque + mutex + not_empty + not_full:
1、Queue内部维持了一个deque对象,用于实现基本的队列操作。
2、mutex属性持有一个互斥锁,确保多个线程访问、修改队列时的互斥性,从而保证线程安全。
3、通过两个条件变量:not_empty、not_full,实现阻塞特性,从而更简洁地控制线程何时应该等待或者被唤醒,实现生产者消费者模型的同步机制。
所以,总结来说,Queue是1个基础的双端队列作为容器,持有一个互斥锁确保线程安全,通过非空、非满条件变量实现阻塞特性。
deque与Queue的简单比较
最后,我们来简单比较一下deque和Queue,从而后面更好地根据实际需求场景进行更好的选择。
1、线程安全特性
Queue是线程安全的,deque是非线程安全的。
2、阻塞操作
Queue是支持阻塞操作的,deque是不支持阻塞操作的,可以通过循环判断,反复确认队列的状态,会对CPU带来更多的消耗。
3、最大长度支持
deque是支持最大长度的,Queue内部也是通过deque来实现的,也是支持最大长度的。
4、阻塞超时机制
deque不支持阻塞,自然也不具备阻塞超时机制,Queue是支持的。
5、使用场景
Queue适合多线程、多进程的并发场景;deueue在单线程中更适用,而且性能较好。
总结
本文通过一个上下游任务协同的需求,引入了生产者消费者模型,同时通过两种方式模拟了生产者消费者模型的实现。最后,简单比较了deque和Queue的主要区别和适用场景。
感谢您的拨冗阅读。